

At the core of any data governance practice is a repository which houses the information needed to store, search, and classify an organization's data assets. This repository acts as a system of record for the data governance team.
In most organizations, the tool of choice for this system of record is the spreadsheet which is often coupled with a document repository such as Microsoft Sharepoint™. This approach has some serious design flaws and there have been many instances of projects based on this design failing disastrously.
The key point to consider is that in most large organizations, the production or consumption of data can be extremely complex. This complex and multi-dimensional landscape is not easily captured within a two-dimensional spreadsheet (rows and columns). Once three or more dimensions are required, additional spreadsheets are added to the mix. With each new spreadsheet comes greater complexity and an exponential amount of manual effort.
At some point, the effort to maintain this environment outweighs the value it returns and the apple cart tips over.
Also, what about using this data for decision support?
Let's say in a perfect world the data governance team is able to capture all of the required dimensions in a manageable series of spreadsheets. The next challenge becomes how do you make this data consumable by others? How do you use this data for analysis? How can we use this data to support decision making?
Capturing the data is only part of the problem. With a spreadsheet-based approach, the data governance team will struggle to make this environment available to others outside the team (it is after all, a complex series of interconnected spreadsheets). This group will also struggle to build a reporting and analysis capability on top of this complex environment.
"We thought we did an OK job collecting the data but we found it impossible to perform even the simplest analysis. We still struggled to understand the impact of change." - Data Executive at a large bank.
The goal of collecting information about the organization's data assets is to support decision making. Yet, the ability to operationalize this information and make it available to others is often not considered during the design stage. This is a serious oversight.
Process Tempo Offers A Better Alternative
Process Tempo is a modern analysis platform designed to support complex, multi-dimensional data. It has built-in analysis features the data governance team can immediately benefit from. It also provides a web-based, easy to use interface, that enables this information to be accessible to a broader user base.
Using Process Tempo as a system of record provides a flexible, yet consistent platform to help the data governance team support critical decision making.
By capturing information in an easy to use, searchable, interface, the number of questions that can be asked become limitless and the value the answers can provide, immeasurable.
"I really love this tool! We could not deliver change without the insight Process Tempo provides." - Business Intelligence Analyst at a Large Pharma Organization.
How Does Process Tempo Work?
As you can see from the following diagram Process Tempo is able to collect multi-dimensional data as well as capture the relationships that exist between these data points. This ability is a game-changer for the data governance team.

A data governance practice must be able to capture the following dimensions as well as the details on how they interrelate:
Data Assets - examples include databases, reports, files, etc.
Stewards - the people who own, or are responsible for, an asset
Consumers - users (or groups) who depend on this asset
Applications - defines where this data is produced, consumed, or hosted
Asset Property - these are key data attributes (such as customer information) that often needs to be tracked per asset
Transformation Process - an ETL process or script that creates or modifies data assets
Domain - the part of the business dependent on this information
Key Performance Indicator - Also known as a metric, these values are often critical to the business and must be closely measured
Glossary/Alias - since terminology varies from department to department it becomes necessary to capture terminology differences in order to avoid confusion
Note: In Process Tempo, these topics or categories are completely customizable and managed via a "Catalog". Catalogs enforce consistency so that the data entered into Process Tempo contain less errors.
Note: The challenge of maintaining consistency can be extremely difficult when using a spreadsheet-based approach. Spreadsheets are inherently flexible but this flexibility can also be their downfall. Process Tempo overcomes this challenge by enforcing the use of data catalogs.
Exploring and searching the data
Data added to Process Tempo becomes instantly available using a Google™-like search bar. The Process Tempo search engine is in fact based on Google's concept of a Knowledge Graph. This makes it very easy for a user to find the information they need and to understand how this data is connected to the rest of the organization.
Imagine being able to track down the source of a key business metric and understand how this metric is used by the business? Imagine knowing which reports use which metric? Imagine understanding which applications produce or consume this data? Who owns this particular asset? What happens if it is changed? This is the power of Process Tempo.
In contrast, the issues with the spreadsheet approach become abundantly clear:

A Real-World Example
The moving parts involved in a report titled "Customer 360 Report" can be quite complex. This complexity would be hidden in spreadsheets but in Process Tempo it can be mapped and made much more clear:

This report, along with many other components of this infrastructure, are highly dependent on the data asset "OPP_FDS_DATA" (highlighted in the middle of the image). What is not displayed in this image are the properties of this asset which are available when hovering over it within Process Tempo.
In this case, the properties for this asset:
Name: OPP_FDS_DATA
Description: A data mart that contains data from our CRM and Helpdesk systems to support the Sales Analytics team
Vendor: Microsoft
Version: MS Access 2000
End of Life: Expired
Status: Obsolete
Reviewing this data uncovers the fact that such a high dependency on an obsolete platform represents a serious risk. Would this dependency have been evident if the data was stored across a number of spreadsheets? The clear answer is NO.
Each object in Process Tempo (what we call "concepts") can have a customizable set of properties. Connected to the OPP_FDS_DATA database is an ETL process called "CRM Offload Process". Viewing the properties of this concept:
Name: CRM Offload Process
Description: Extracts data from SFDC
Author: John Doe
Type: ETL Transformation
Vendor: Spoon
Last Modified: March 11, 2003
Last Ran: September 16, 2015
Given that the year is now 2019 there may have been some changes to either the source or target data sources since the last time this process was modified 16-years prior! Let's not even bring up the fact that the ETL process itself was last run in 2015!
A Note On Complexity Scoring
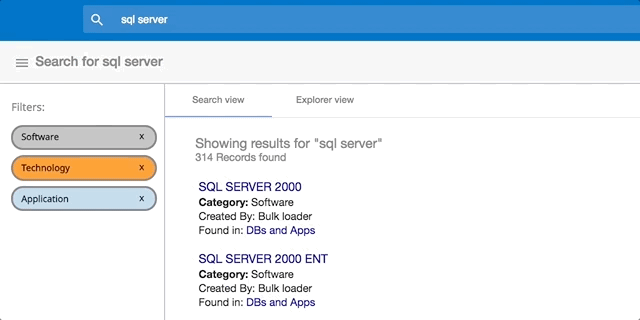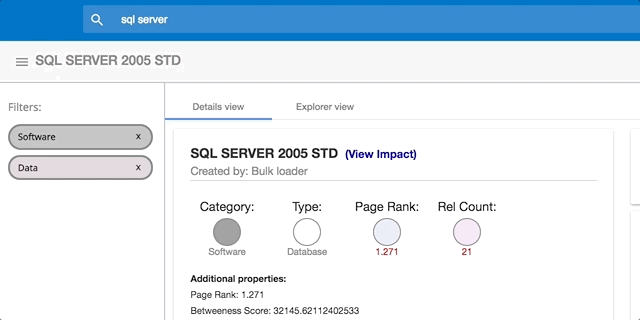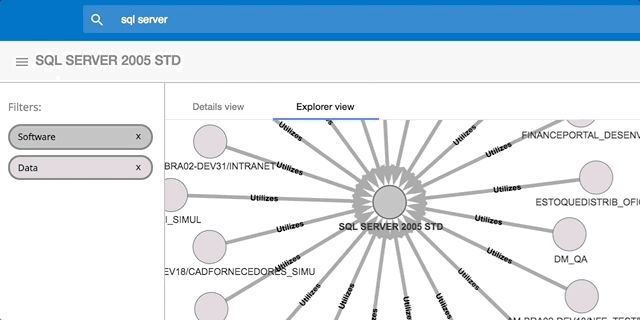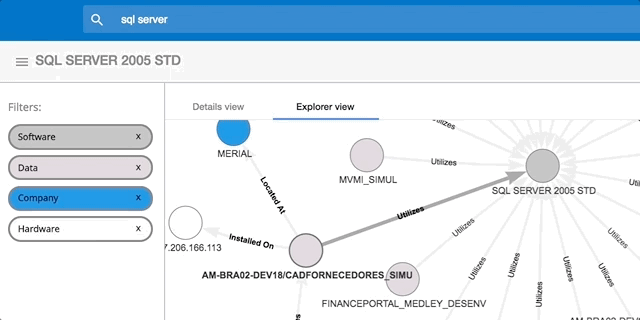
Process Tempo has built-in advanced scoring features so that users can understand the interconnectedness of certain concepts. We offer Page Rank scoring and Relationship Count scoring out of the box and these values are automatically calculated as data is loaded.
These algorithms simply look at the number of inbound and outbound connections that exist for each object. The Page Rank considers the strength and direction of the connection whereas the Relationship Count does not.
This scoring becomes helpful during planning and analysis. Evaluating and comparing data assets can be done with these scores in mind. For example, Report "A" with a Page Rank of "100" would be instantly recognized as being more complex (or critical) compared with a report with a Page Rank of "1".
There are several additional analysis features built-in to Process Tempo and customized analytics can be added as part of an implementation.
How is data loaded into Process Tempo?
So far we have demonstrated the unique and powerful ways in which Process Tempo can help analyze data assets. The next question: how is this data loaded into the platform? Thankfully, there are several options:
Manual data entry via our Visual Modeler
Bulk loading data via our Import Model feature
Loading data via existing ETL capabilities
Option #1) Manual Data Entry
Users can add their own data and associated properties using the Process Tempo Visual Modeler. This is a drag-and-drop environment requiring minimal training. Users select concepts from a catalog of available items and drag them onto the model canvas using their mouse. After adding it to the canvas, a property editor appears allowing the user to enter additional information. Both concepts and relationships can be captured in this manner.

Option #2) The Import Model
The Import Model tool allows users to import data in .CSV format and map this data to concepts and properties within Process Tempo. In this manner, we can take advantage of any existing work done in spreadsheets. The Import Model feature utilizes the same drag-and-drop simplicity as the Visual Modeler.

Option #3) Leverage Existing ETL Capabilities
Most large organizations have invested in Extract, Transform, and Load (ETL) platforms such as IBM Datastage, Informatica, Pentaho, etc. In these cases, the data governance organization can utilize these platforms to load data directly into Process Tempo.
Process Tempo can provide ETL services as part of an implementation.
What sources of data can the Data Governance Team tap into?
There are a number of places where information about the production or consumption of data assets can be found:
Helpdesk systems - Data from your SerivceNow™ or BMC Remedy™ instances (for example) can prove to be very insightful. From this system we can get an extract of all of the data sources (aka the applications) that are in use as well as the people that use them
Business Intelligence repositories - server-based BI platforms often utilize a database for storing report assets. This is a good place to start. Log files from these systems can also be helpful. By understanding when a report was last accessed we can determine its value to the organization
ETL Metadata and Logs - most ETL vendors provide logging information and metadata. Leveraging this data can help understand data lineage
Existing Spreadsheets - likely the best place to start is any existing data maintained in spreadsheets
Using Process Tempo, the data governance team can easily import data from multiple sources into a single composite view. By doing so, they will have access to a 360-degree view of their data - perhaps for the very first time!
Summary
Organizations relying on spreadsheets to capture the complex intricacies of data governance should consider a different approach. The two-dimensional confines of a spreadsheet ultimately become very difficult to maintain and furthermore, they lack the analytical capabilities the data governance organization requires. These approaches are often designed without an appreciation for the complexity involved nor designed to support decision making.
Process Tempo is different. It offers a new and intuitive approach to capturing and analyzing multi-dimensional data. It comes with built-in features that will greatly enhance the capabilities of the Data Governance team. It was designed for the non-technical user which means the data collected is easier to understand and can serve a greater number of purposes.
Before your organization sets off on a data governance project, please consider your options first! We encourage you to contact us to learn more. We are always happy to help!